


Generative Adversarial Networks (GANs) have obtained extraordinary success in the generation of realistic images, a domain where a lower pixel-level accuracy is acceptable. However, there are scenarios (like those we face here at Zuru Tech), in which the GAN output must be precise at pixel level. These are cases in which the generated image should be "machine-readable" without post-processing.
The two main scenarios in which we need pixel-level accuracy are:
- Semantic Segmentation
- Semantic Image Generation
In this work, we focus on Semantic Image Generation, even if our architecture can be applied also to the problem of Semantic Segmentation. Applying the standard GAN architecture to the task of (unconditional) Semantic Image Generation results in colors (and thus labels) not well defined, and a not-neat class distinction.

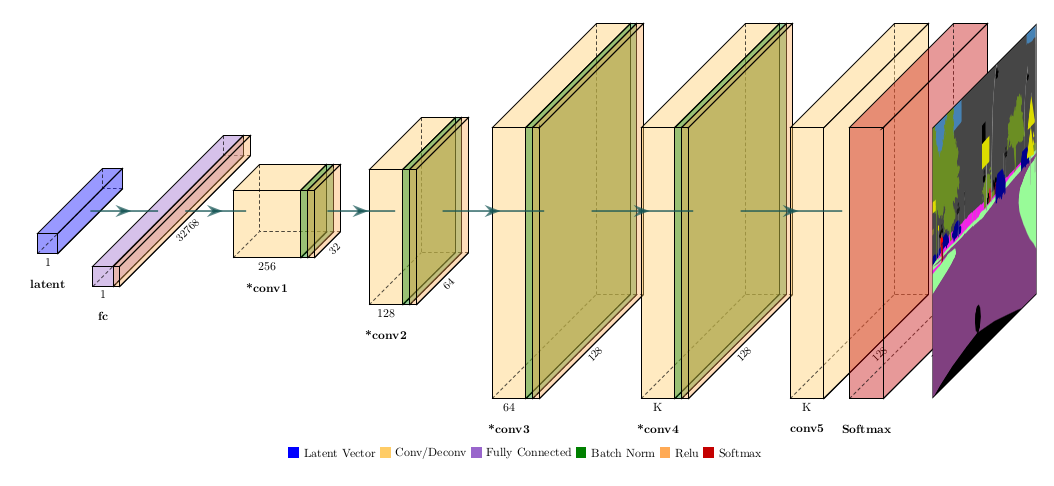
In our paper, Adversarial Pixel-Level Generation of Semantic Images, we propose a new GAN architecture, SemGAN, able to solve the problem of inaccurate output modeling directly the class distribution instead of the label color.
We compared our architecture with the standard GAN architecture on three datasets. Moreover, we propose an interesting application in which we let our network "dream" realistic street scenes, feeding a Pix2Pix model with the output of our generator.
For more details, please see our paper.
This work was done by our ML&CV Team: Emanuele Ghelfi, Paolo Galeone, Federico Di Mattia, and Michele De Simoni.