


 Managing Machine Learning experiments is usually painful.
Managing Machine Learning experiments is usually painful.
The usual workflow when approaching a problem using Machine Learning tools is the following. You study the problem, define a possible solution, then you implement that solution and measure its quality. Often the solution depends on some parameters, and we refer to the set of parameters with the term configuration. Parameters can include model type, optimizers, learning rate, batch size, steps, losses, and many others.
The configuration profoundly influences the performance of your solution. If you have enough time and computational power, it is possible to use a Bayesian approach for solving the hyper-parameter selection problem, but in real situations, it is common to perform a limited set of experiment and select the best configuration among them.
In this article we describe how to manage experiments in a good way, ensuring inspectability and reproducibility. We focus on Machine Learning experiments in python using Tensorflow even if this approach applies to all computational experiments.
Simple (Bad) Solution
To keep track of the configuration the usual way to go (at least in Tensorflow) is to save your models and logs inside a folder with a shared pattern for the parameters name and value.
Using this setting with Tensorboard (the official Tensorflow visualization tool), it is possible to relate the plot to its configuration. However, this is not the right way to manage experiments since it is tough to see how parameters affect performance. Tensorboard offers none way to order experiments by configuration, selecting only some experiments or order experiments by performance. In this way, we do not have any control and tracking of our source code, except for our VCS. Unfortunately, when doing experiments, we do not always push our changes since they might be tiny changes or only trials, this can cause issues since our experiments might not be reproducible. We can implement an experiment using this style in the following way:
# other imports ... import tensorflow as tf def get_logdir(config): logdir = "" for key in config: logdir = logdir + f"_{key}_{config[key]}" return logdir def main(): # load the configuration config = load_config() # load dataset, model, summaries, loss using the configuration # merge summaries summary_op = tf.summary.merge_all() # define a logdir to keep track of the configuration logdir = f"logs/{get_logdir(config)}" # instantiate a tensorflow saver saver = tf.train.Saver() writer = tf.SummaryWriter(log_dir) with tf.Session() as sess: # train loop for step in range(config['steps']): # your training code ... loss_value = sess.run(loss) # write summaries writer.add_summary(summaries, step) writer.flush() # save model saver.save(sess, logdir)
In this code snippet, we load the model, dataset and other possible configurations, the logdir defined is needed for associating a configuration to the right plot in Tensorboard. In this way we obtain the following folder structure using only 4 parameters:
├── lr=0.0002_batch_size=32_kernel_size=5_steps=100 ├── lr=0.0001_batch_size=32_kernel_size=5_steps=100 ├── lr=0.0002_batch_size=32_kernel_size=7_steps=100 ├── lr=0.0002_batch_size=16_kernel_size=7_steps=100
Logging experiments in this way is not very comfortable, and it is not the right way to manage experiments and make them reproducible.
Sacred Solution
Every experiment is sacred
Every experiment is great
If an experiment is wasted
God gets quite irate
Sacred is a tool that lets you configure, organize, and log computational experiments. It is designed to introduce a minimal overhead and code addition.
With sacred you can:
- Keep track of all parameters of your experiment
- Run your experiment with different settings
- Save configuration and results in files or database
- Reproduce your results.
Sacred dumps and saves everything into MongoDB including:
- Metrics (training/validation loss, accuracy, or anything else you decide to log)
- Console output
- All the source code you executed
- All the imported library with their versions used at runtime
- All your configuration parameters
- Hardware spec of your host
- Random seeds
- Artifacts and resources.
To visualize and interact with your experiments a nice visualization board for this tool is Omniboard.
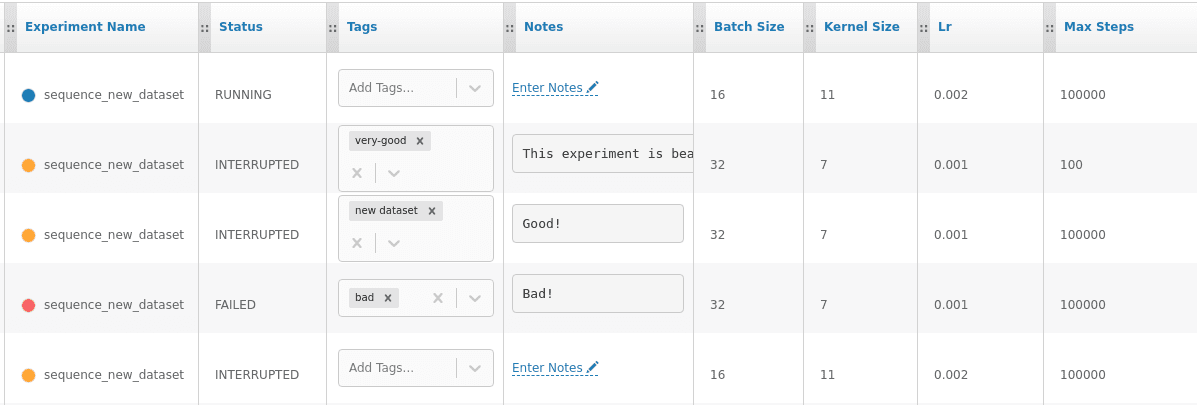
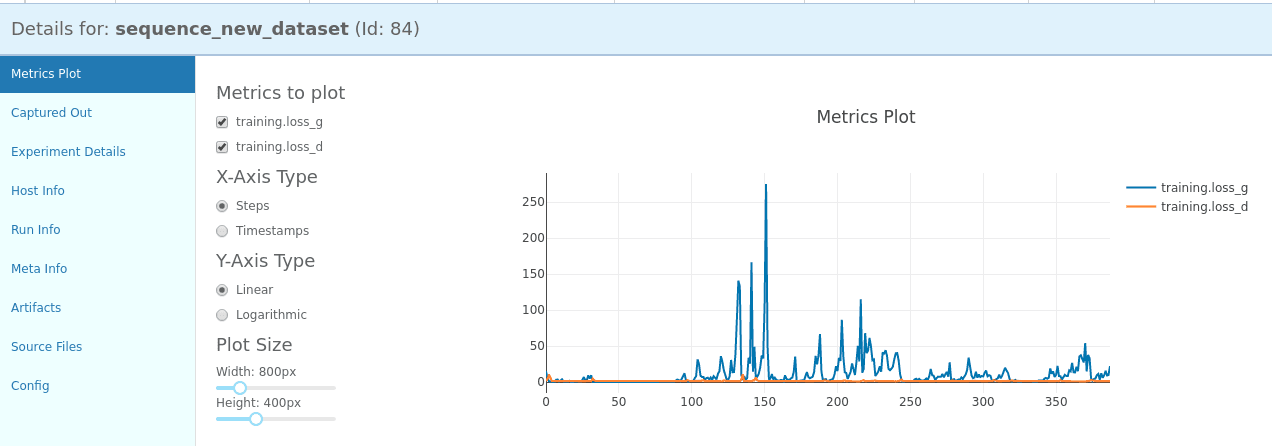
Omniboard lets you tag, annotate and order experiments making inspection and model selection easy.
Sacred Integration
Integrating sacred in your code is painless. The previous code becomes:
# other imports ... # tensorflow import tensorflow as tf from tensorflow.python.training.summary_io import SummaryWriterCache # sacred from sacred import Experiment from sacred.observers import MongoObserver # instantiate a sacred experiment ex = Experiment("experiment_name") # add the MongoDB observer ex.observers.append(MongoObserver.create()) # load the configuration ex.add_config("default.json") ex.add_config("experiment.json") @ex.automain @LogFileWriter(ex) def main(batch_size, learning_rate, steps, ... params, _run): # load dataset, model, summaries, loss using the parameters # merge summaries summary_op = tf.summary.merge_all() # define a logdir using the experiment id of sacred logdir = f"logs/{_run._id}" # instantiate a tensorflow saver saver = tf.train.Saver() writer = tf.SummaryWriter(log_dir) with tf.Session() as sess: # train loop for step in range(steps): # your training code ... loss_value = sess.run(loss, feed_dict) # log loss to sacred ex.log_scalar("training.loss", loss_value, step) summaries = sess.run(summary_op, feed_dict) # write summaries as tensorflow logs writer.add_summary(summaries, step) writer.flush() # save model saver.save(sess, logdir)
In this way, we create a new instance of Experiment and an instance of MongoObserver to store data to MongoDB. We add two different configurations, a default configuration (default.json) and an experiment configuration (experiment.json). The function decorated with @ex.automain is the main function of the experiment and Sacred automatically injects its parameters. The LogFileWriter(ex) decorator is used to store the location of summaries produced by Tensorflow (created by tensorflow.summary.FileWriter) into the experiment record specified by the ex argument. Whenever a new FileWriter instantiation is detected in a scope of the decorator or the context manager, the path of the log is copied to the experiment record exactly as passed to the FileWriter. The location(s) can be then found under info["tensorflow"]["logdirs"] of the experiment.
Using this approach the folder structure is clean (folders are named with a progressive id) and we detach the folder name from the actual experiment configuration.
Conclusion
Managing experiments in a more efficient way is a crucial priority, especially when doing research. Reproducibility is an essential requirement for computational studies including those based on machine learning techniques. Sacred is a potent tool, straightforward to integrate into your codebase, saving you the effort of developing a custom way to keep track of your experiments.