


Deep learning is not just data-intensive but also computationally voracious. When you are training GANs, and you want to move on from small MNIST 28x28 images to larger and more vibrant photos you either accept abysmally low batch size capable of fitting on one GPU or you try and go big by tapping into the power of distributed and parallel computing.
Horovod?

Horovod is a distributed training framework for TensorFlow, Keras, and PyTorch. The goal of Horovod is to make distributed Deep Learning fast and easy to use.
The primary goal behind Horovod is a noble one: making distributed training (and in general distributed computing) using TensorFlow (Keras or PyTorch) fast and straightforward.
A plug and play API that minimizes its interference in the codebase coupled with an MPI based implementation of the Ring-Allreduce, an algorithm initially proposed in a 2009 paper that was given an experimental TensorFlow adaptation by Baidu in 2017.
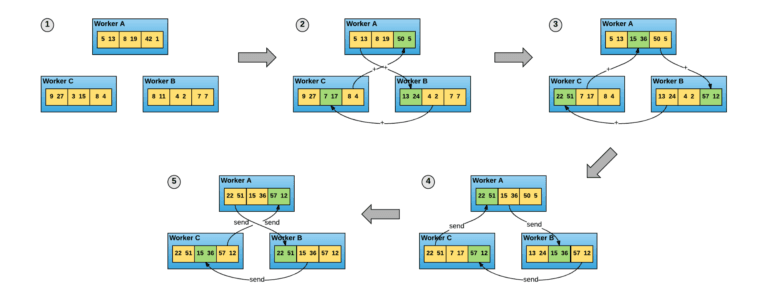
The core idea behind this radically more efficient approach (as demonstrated by their benchmark) is to get rid of the centralized parameters servers and let each node communicate with each others multiple time, each time changing the partners and thus letting the workers average the gradients gradually dispersing them over the entirety of the network.
With great powers come great connectivity (issues)
Horovod is undoubtedly simple to apply to a codebase, the modifications needed are quite simple and straightforward; however, this does not mean that it easy to set up running.
The most annoying problem we came across was the complete lack of feedback in some cases, by looking at a just a couple of issues on GitHub, you can see that many laments Horovod just hanging without any output. This behavior can be caused by different causes (in our experiments the two likeliest culprits were errors related to either SSH or Horovod trying to use the wrong interface).
Though the most glaring issue with Horovod is its connectivity hunger, distributin gcomputation on a single node was relatively simple, painless, and quick to set up; when trying to scale up by increasing the number of nodes instead we immediately hit an unexplained 10x drop in performance.
Debugging it was a painful endeavor.
At first, we blamed our configuration, having used Arch Linux we thought that there could have been a mismatch between NCCL and our pinned Cuda 9.0 version resulting in suboptimal performance thus resorting to run it as a self-contained Docker.
The Docker way had its share of obstacles, some of which were promptly fixed by the devs soon after we reported them coupled with others which we are still investigating before reporting (like an apparent lack of sshd inside the Dockerfile used in the Docker guide).
However even after getting the container up and running, we saw the same situation happening again. Running on multiple nodes (4 GPUs) had sluggish performance and was overall slower than training on just one GPU.
After scouring through old issues, we found one, "horovod performance decrease dramatically when run on multiple server" which seems to explain our significant performance drop.
While we are experienced deep learning practitioners, it was the first time we needed the computational power and scale offered by something like Horovod, we thought we could make it do with our network, but apparently, it is not the case.
Considering that Horovod sells itself as the simple yet effective library aimed at the data practitioner and not at the distributed computing expert, a little disclaimer on the connection voracity would have gone a long way.
Conclusion
- The Good: simple to use in code, on a single node works flawlessly
- The Bad: multinode setup requires additional hardware and networking configuration (25GbE minimum)
- The Ugly: lack of up to date well-groomed docs with practical configuration examples and the likes of them.
I recommend Horovod to every developer with access to a proper HPC capable network or a single powerful machine. Having said that the jury is still out on the best way to distribute TensorFlow training since Google has announced a new whole set of distribution strategy for TensorFlow 2.0. Stay tuned to learn more!
May the hyperparameters be with you.